Why Multi Window Multi Burn Rate SLO Alerting Sucks!
Service Level Objectives (SLOs) are great! Alerts based on SLOs are great! Alerts based on SLOs promise to reduce noise by only alerting on true service degradations, reducing noise and alert fatigue. Everyone uses the multi-window multi-burn-rate (MWMB) method for defining SLO alerts, because Google recommends it. But now that I've seen how this alert behaves in the real world, I think it's an overcomplicated mess with too many moving parts that interact in confusing ways to create alert spam that is hard to explain. Simply removing some of these moving parts can improve your on-call experience.
Why SLO Alerting?
Let's recap the basics! I have a web service Foo which my users depend on. My users are cranky, impatient, and will have a meltdown if a request to Foo takes more than 300ms. I can handle a handful of users in full meltdown, but I will have a real problem if more than 0.1% of my users have a meltdown. I must therefore always track how close I am to this scenario.
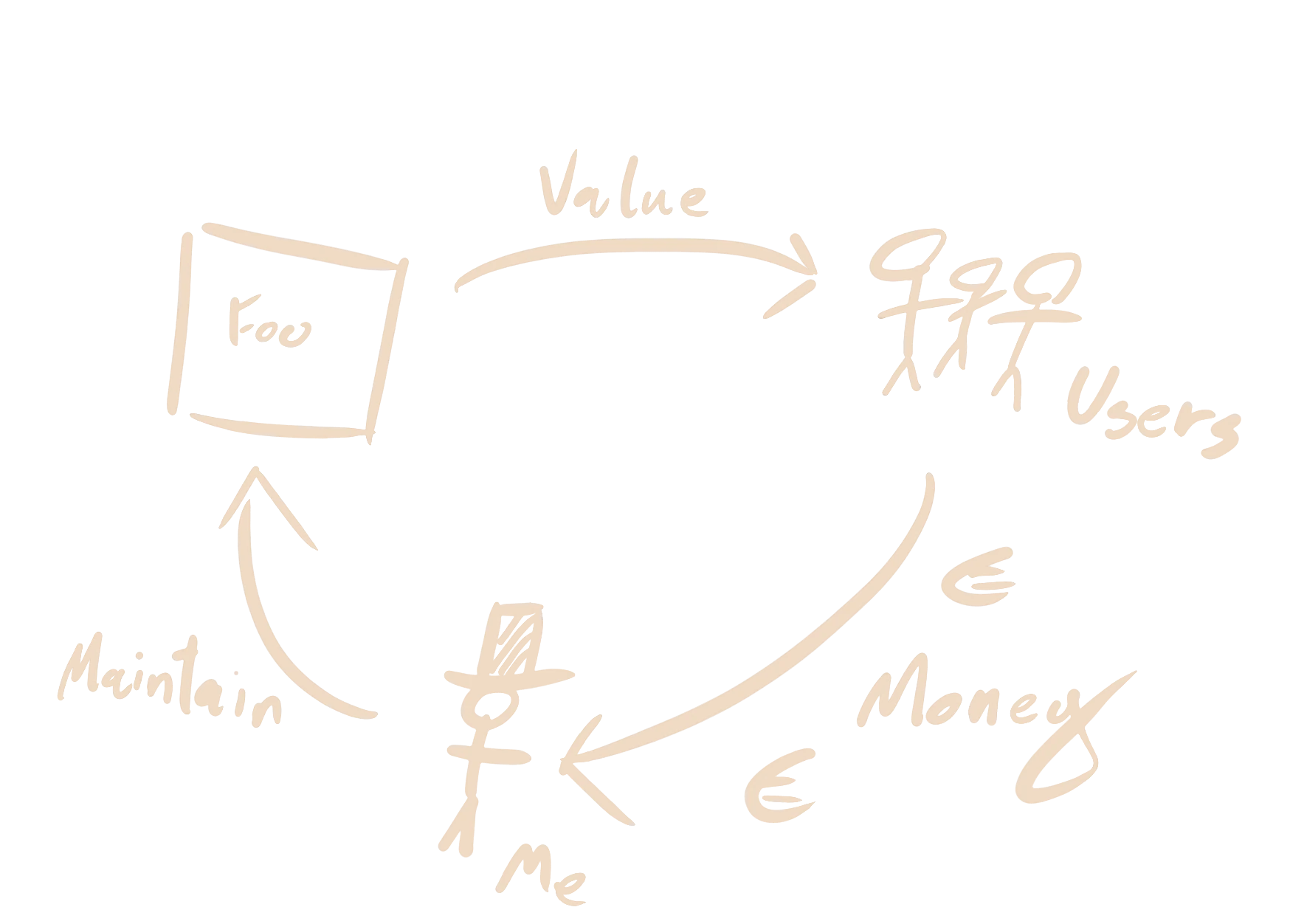
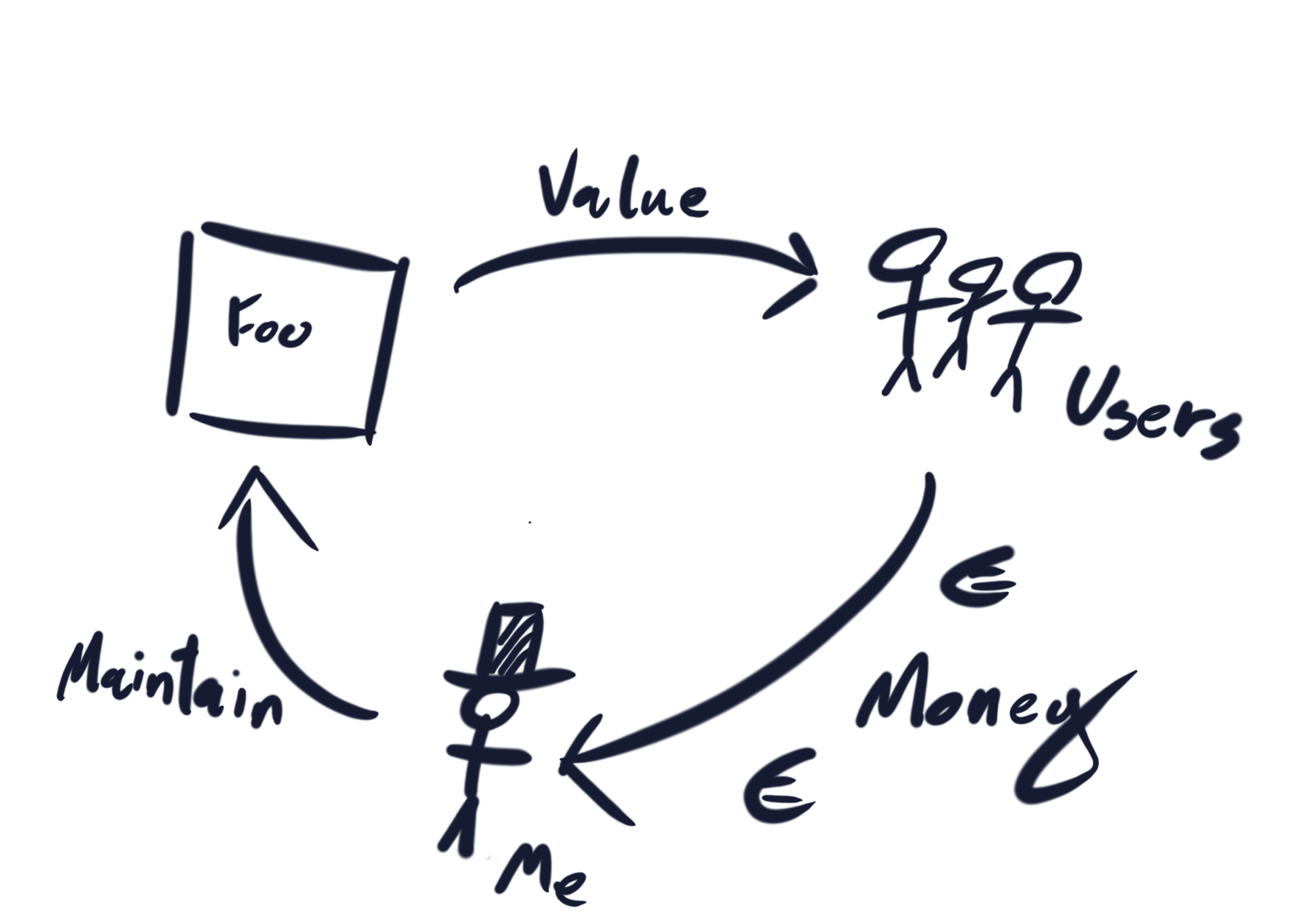
This is not difficult with SLOs. I simply record the latency of each request and count how many requests take more than 300ms. My users have short attention spans and completely forget anything that happened more than 30 days ago. For this reason, I record requests over a 30-day rolling window. In SLO terms, this means I have a budget of 0.1% slow requests over the last 30 days. Every slow request burns a little bit of that budget. The speed at which I'm burning through my budget is the burn rate, where a burn rate of 1 means that I am on track to deplete my budget at the end of the 30 day period. If I can act quickly to ensure that I never deplete my budget, then I will always have a manageable number of cranky users.
But how could I possibly ensure this?! My Foo service is a hideously complicated spaghetti monolith that knows my schedule in intricate detail, and plots to fail precisely when I am least likely to be paying attention, and fails in ways that I am least likely to notice. I can set up alerts on every metric that moves, alerts on CPU utilization, packet loss, too many pending k8s pods, disk failures, but Foo service, in its machinations, will always devise a new, more cunning, way to fail. By the time I notice, it will be too late. Budget: depleted. Users: cranky.
What if this could all be resolved with a single alert? One alert that could catch all failures. One alert that could never be a false positive. One alert that doesn't need to change when implementation details of Foo are changed. SLO based alerting promises precisely this. If I alert on the symptom that I care about, rather than all the possible causes of that symptom, then I can be sure that I notified when that symptom arises. The question that remains is how do I define an alert on an SLO?
Multi Window Multi Burn Rate Alerting
Luckily, Google already has the answers. If you haven't, go read Alerting on SLOs from chapter 5 of the Google SRE Book. It's great, and nothing I say will make any sense if you haven't read it. But I will restate Google's final and recommended solution for SLO alerting for your convenience.
Google are interested in optimizing 4 things:
- Precision: Alerts should only fire for real issues. No false positives!
- Recall: Real issues should cause alerts to fire. Don't miss issues!
- Detection time: Alerts should fire quickly after a real issue begins.
- Reset time: Alerts should quickly resolve after an issue has resolved.
Take a moment to appreciate that these 4 goals are in conflict. If I'm worried about an alert potentially missing issues, I can reduce alerting thresholds. But, this will make the alert noisier and increase the number of false positives. Conversely, I can reduce false positives by increasing the alerting threshold, but this could increase detection time or lead to missed issues.
You might be thinking to yourself:
These goals are all well and good, but I don't have the time to be fiddling with alert parameters to balance all these goals for all of my SLOs!
But it turns out that a single method, with a single set of parameters, can work quite well for a large class of SLOs. Google makes one critical insight: The rate at which a service is burning through its budget is the only piece of information you need to determine the criticality of a potential alert. This means that an alert defined in terms of the budget burn rate will work equally well for different types of services, and with different budgets.
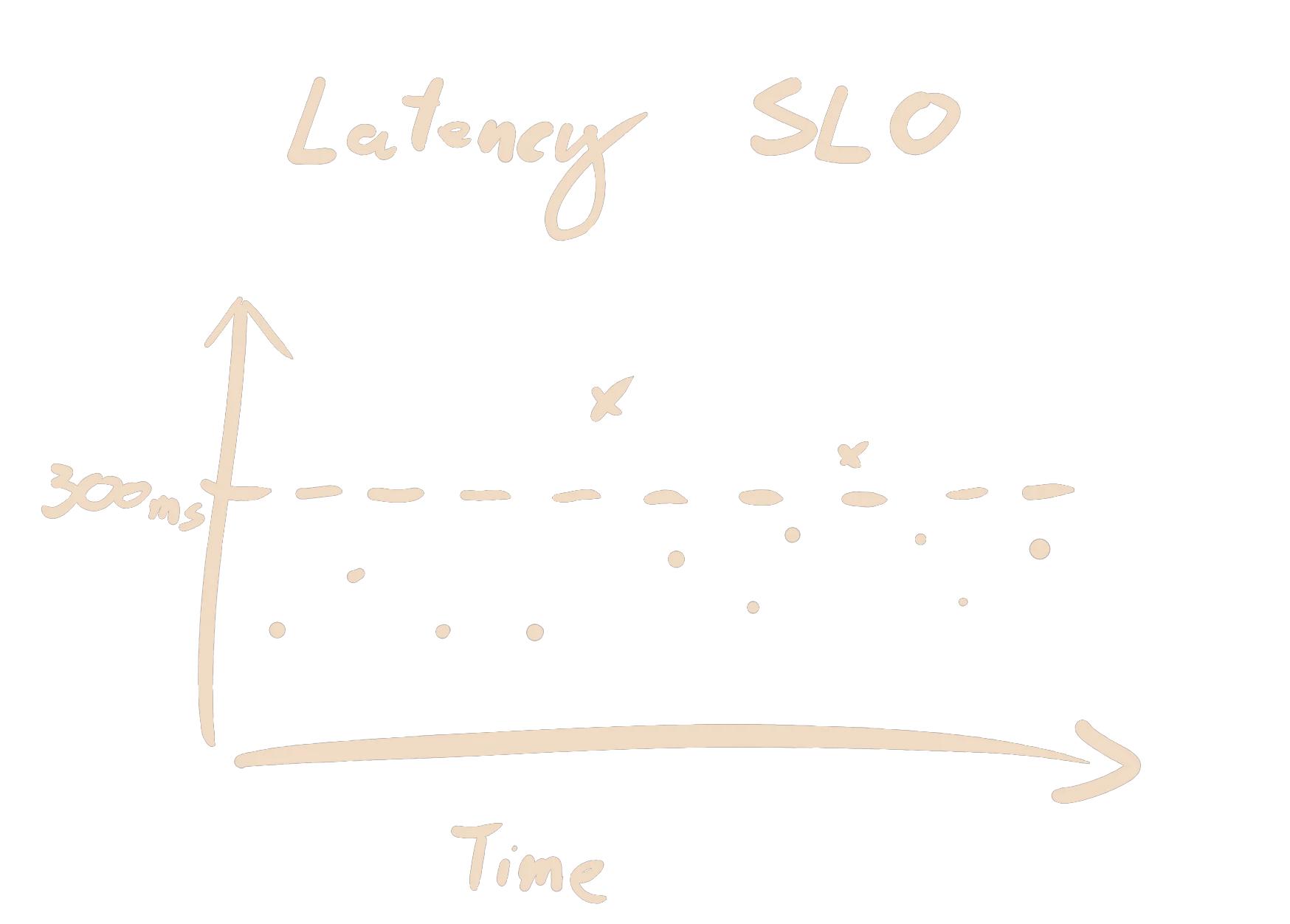
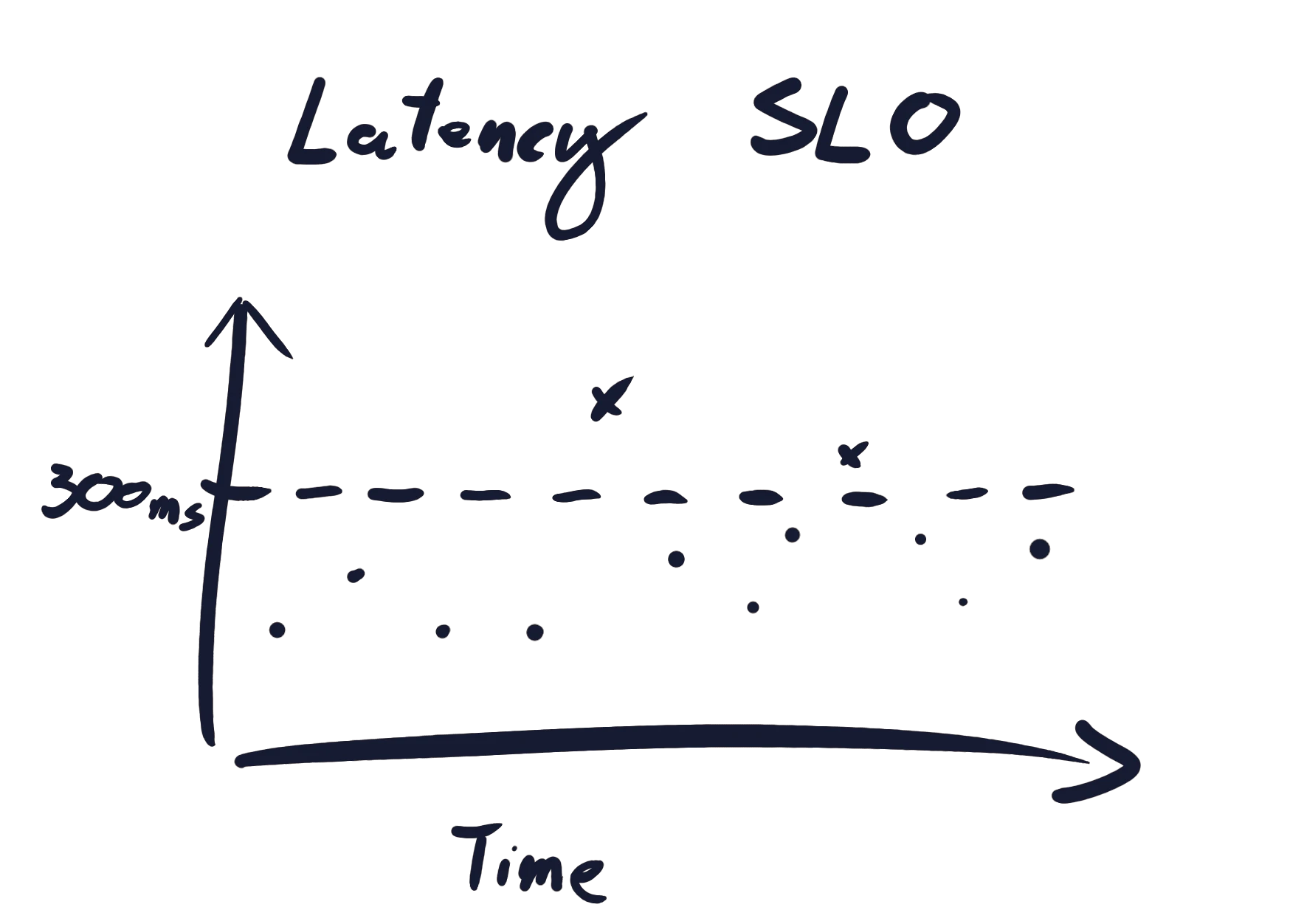
Let's return to my Foo service. If in the last 5 minutes, 0.05% of requests were slow, then I am burning through half my budget (0.1%) in that 5-minute period. This is a burn rate of 0.5. If my burn rate always stays below 1, then I will never deplete my budget. If the importance of Foo service grows and management forces me to limit cranky users to 0.01%, then the simple fact remains that a burn rate below 1 is what I need to achieve. Conversely, a burn rate consistently above 1 means that I will deplete my budget. If the burn rate is 2, then I will run out of budget in 15 days. If the burn rate is above 100, then my entire budget will be depleted in a few hours. This is precisely when I want to be alerted!
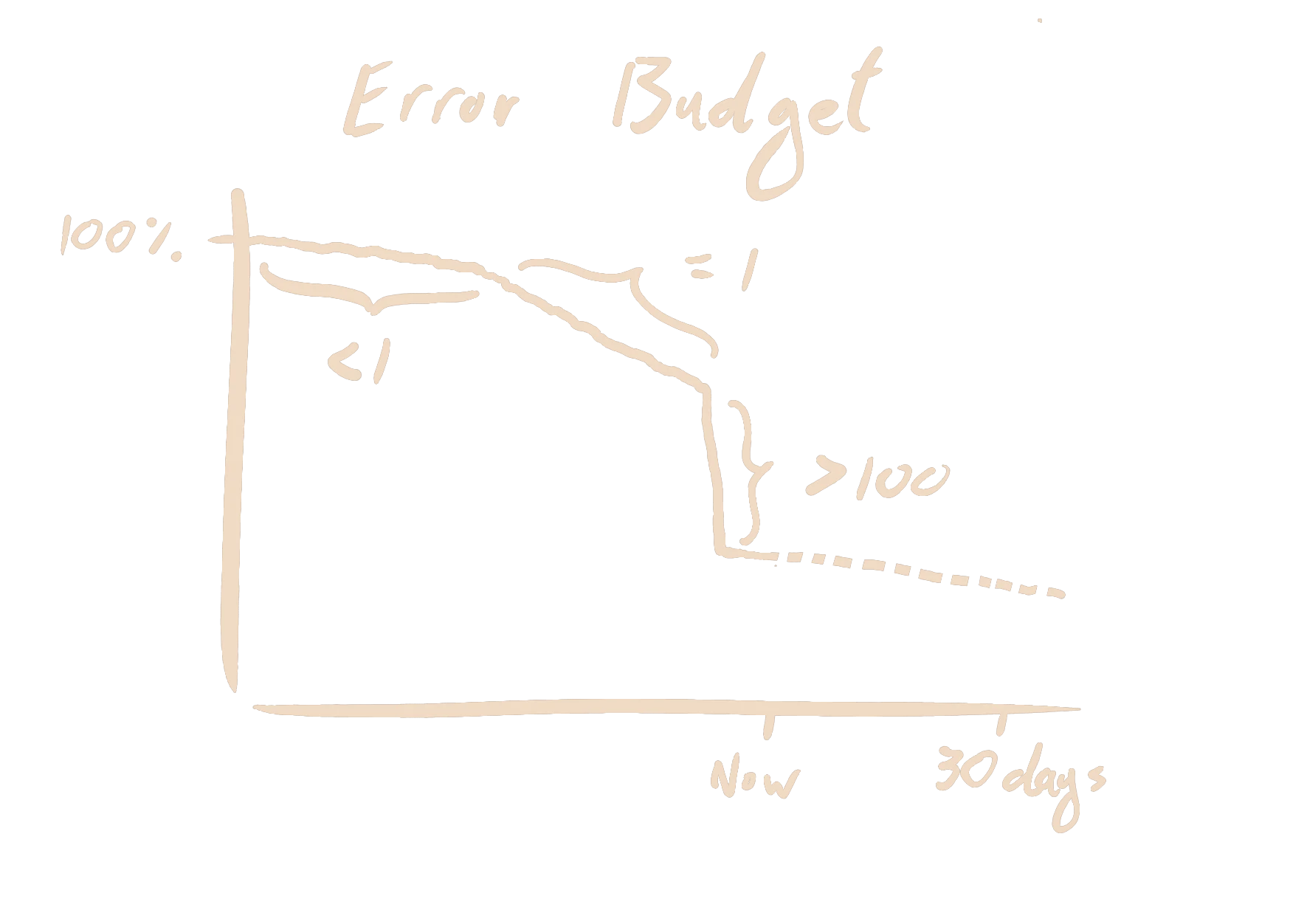

Google then propose to construct an alert from 4 different sliding windows of the burn rate. The 4 windows are split into two pairs. The first pair should detect large incidents quickly, but can miss smaller incidents. The second pair detect issues that the first pair miss, but they can be slower to detect them. Within each pair, there is a short window and a long window, and the burn rate must be above a threshold in both windows for the alert to fire. The short window ensures that the alert resets quickly after the incident is resolved. The recommended parameters are restated below.
| Short Window | Long Window | Burn Rate Threshold | |
|---|---|---|---|
| First Pair | 5 minutes | 1 hour | 14.4 |
| Second Pair | 30 minutes | 6 hour | 6 |
So if I use MWMB SLO alerts for my Foo service, then I will catch all issues in a timely manner and I will not be spammed with alerts. Or will I?
Why This Actually Sucks
If you are reading this, you probably care about SLOs and good SRE practice, and you might be willing to do additional work to improve your SLOs. But let's be honest with ourselves, most engineers don't care in the slightest about work that doesn't directly improve their lives. This matters if you are trying to drive SLO adoption in an older organization. Imagine I am a regular engineer working on my piece of the product. If some snooty SRE tells me I need SLOs for my service which has been running for years, I will correctly conclude that this is work that competes with feature work, and I don't gain anything. When I do eventually implement SLOs, I will dedicate close to the bare minimum amount of time so that I can get back to shipping features.
As an SRE trying to increase SLO adoption, there are two things to take away from this.
- There needs to be a selling point that appeals to the teams that will be implementing the SLOs.
- It needs to be stupid simple, easy to understand, and hard to screw up.
In my time, I've pushed the alerting story, telling teams that they can reduce alert spam with SLO based alerts in order to entice them to create and maintain their SLOs. But I have to admit, MWMB alerts are not stupid simple, they are not easy to understand, and you can definitely screw them up!
If you think that MWMB alerts are simple, then you have a high bar for what you consider to be complex. New engineers that adopt SLO based alerts will ask me, why did this alert fire? Why did this alert not fire? I will have to explain: Oh, it's simple, an alert fires for your service if in the last 5 minutes and in the last 1 hour the proportion of bad requests was 14.4 times higher than your error budget or in the last 30 minutes and in the last 6 hours the proportion of bad requests was 6 times higher than your error budget. Their eyes have glazed over before I can finish the sentence. All the nice theorectical properties of MWMB alerts don't mean anything if users don't trust the alerts. People don't trust what they don't understand.
Flapping
But this is hardly the most annoying part of MWMB alerts. Despite all the nice properties of the burn rate, MWMB alerts can still have false positives. By optimizing the reset times of the alert, Google has also made it possible for the alert to flap (toggle between resolved and alerting in quick succession).
This is especially painful for me, because negative experiences with flapping SLO alerts kills the narrative around improving the on-call experience with SLO based alerts. What I would want to tell people adopting SLO alerts is something along the lines of the following:
This alert will trigger if you've burned through 5% of your budget in a short time period. Hence, you can't have more than 19 ignorable alerts. Since the 20th alert will have depleted your budget, at least one of the issues should have been actionable.
Google actually makes the claim that an MWMB alert does correspond to a fixed consumption of the budget (Either 2% or 5% depending on which burn rate threshold triggers). But this is only true in the ideal scenario where:
- Incidents have consistent impact without any gaps or lulls.
- Incidents will politely avoid impacting a proportion of traffic that closely matches the burn rate threshold (either 14.4 or 6 if you use Google's parameters).
- You have sufficient traffic 24/7, even during incidents.
Incidents have no interest in making your life easy, so obviously 1 & 2 don't hold. Point 3 is addressed by Google, but it's hard for a user to determine what constitutes sufficient traffic.
Let's consider a concrete example to illustrate what can go wrong. I'm working on a highly requested feature for the Foo service when suddenly there is a partial outage that pushes the burn rate up to 30. The 5 minute window will pass above the 14.4 threshold in about 2 minutes and the 1 hour window will pass above the threshold in about 15 minutes. Since both windows need to be above the threshold before the alert fires, the alert triggers after 15 minutes. I declare an incident and my helpful colleague quickly notices that a queue is full. Requests are coming in faster than they can be processed because of a handful of very expensive requests jamming the queue. After the expensive request is processed, many requests can succeed since there is now sufficient capacity in the queue. But, without a proper fix the queue gets jammed again when another expensive request appears.
Every time a burst of requests succeed, incident is resolved only for my pager to buzz when the incident is retriggered a few minutes later. Each burst of successes is enough to bring the 5 minute burn rate below the 14.4 threshold, but not the 1 hour burn rate. So now the alert can retrigger just as easily as it could be resolved. Each time my pager buzzes, I dread that the incident might have caused other downstream failures, only to find out that I'm alerted again for the issue I'm already working on!
Alternatively, if there is an incident, I might decide to divert traffic to a different region or an upstream service may decide to use a fallback instead of calling Foo. Perhaps, even users, seeing that Foo isn't working, will go outside and enjoy fresh air. This could affect the total amount of traffic going to Foo, which will make Foo, temporarily, a "low traffic" service. When traffic is low, luck has a big impact on the 5 minute burn rate. If the target for Foo is 99.99% and traffic has been reduced to 1 request per second, then a single failed request causes the 5 minute burn rate to jump to 33. If the 1 hour burn rate is 20, then we would expect a failed request every 8 minutes ish. Just enough to have the MWMB alert flap between alerting and resolved for every individual failed request!
These types of scenarios might not be common, but they are certainly not rare. If you are on-boarding a large number of teams onto SLOs and SLO based alerts, then it wont take long before you start seeing cases similar to what I outlined above. If it happens too often, then your colleagues wont see the benefits of SLO based alerts and their motivation to implement what you ask of them will evaporate.
The Solution
It might seem like it's impossible to satisfy all four goals of precision, recall, detection time and reset time. Even Google's fanciest methods struggle under non-ideal conditions. As we've seen, all the goals compete with each other. Which then raises the question: if we can't achieve all the goals, which goals are the least important? To me, reset time stands out. In fact, the tooling I use has always allowed me to manually resolve an alert if I was sure the issue was fixed. This makes quick alert resolution a "nice to have" rather than an absolute nessecity.
So if we drop reset time as a goal, where does that take us? Luckily, Google (again) has the answers: multi burn rate alerts (MB). Here there is no short and long window, just one window per burn rate. These have similar same theoretical properties to their multi window evolutions: e.g. detection time and recall are the same. But they have the advantage of being conceptually simpler. Critically, because the shortest sliding window is now 1h instead of 5 minutes, the SLO alert is also more stable and can tolerate lower traffic and erratic incidents without flapping, which improves precision. This doesn't mean that flapping is now impossible, but the original narrative of an alert corresponding to a fixed loss of budget is now much closer to being true.
So unless you really need short reset times for your SLO alerts, ditch the complexity! Keep it simple, just use multi burn rate alerts.
Appendix: What is sufficent traffic?
Terms like "low traffic" or "sufficient traffic" are thrown around without much explanation. The more traffic you have, the better all these alerting methods behave, because each sliding window will have more data points in it. This makes the individual effect of each request smaller, so you are less sensitive to outliers or just bad luck. But how much traffic should you have?
Of course, this is somewhat subjective because it depends on how much you care about false positives caused by low traffic. But if you just want to rough number to start with, here is my recommendation for both alerting methods.
| SLO Target | Min. Throughput for MWMB Alerting | Min. Throughput for MB Alerting |
|---|---|---|
| 99% | 0.3 req/s | 0.03 req/s |
| 99.9% | 3 req/s | 0.3 req/s |
| 99.99% | 30 req/s | 3 req/s |
| 99.999% | 300 req/s | 30 req/s |
These numbers were chosen so that the variance of the shortest sliding window used in each alerting method stays close to 1. This assumes that requests can be treated as i.i.d. Bernoulli trials with success probability equal to the SLO target. The exact numbers are just for reference, the important point to remember is that traffic needs to grow 10x for each additional 9 to keep the same variance.